Work undertaken at the LATL in recent years was basically focused on problems linked to natural language syntax processing, both in the perspective of pure research and of its application to typical issues of the language industries. It has led on the one hand to the development of a cognitive model of parsing (Walther 1997), and on the other hand to the creation of syntactic parsers of English, German, French..., based on Chomskyan models of formal linguistics. These parsing tools and their lexical databases were the starting points for several projects of written/spoken language processing prototypes and systems. Such projects include:
The language parser, called FIPS, is also used as a tagger in the GRACE evaluation project. It is also partly integrated in a French learning software developed in the framework of SAFRAN, an 'ARP' project led by the AUPELF in collaboration with UMist/Manchester, ENST/Paris, IDIAP/Martigny and the University of Sofia.
Project IPS aims at developing interactive parsers for various languages, based on the linguistic model of GB theory.
The goals of project IPS are at the same time theoretical and practical. On the one hand, we try to show the feasability and interest of chosing an automatic parser based on a modular linguistic theory, where general principles replace specific rules of traditional phrase-structure grammars. On the other hand, we aim at developing a powerful parser suitable for practical uses in the field of language processing, and in particular in computer-assisted translation or speech processing.
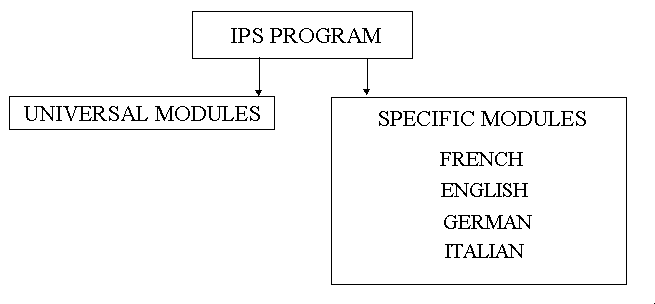
From a practical point of view, IPS is a single program composed of universal modules (common to all languages) and of modules specific to each language, as shown in Figure 1 below.
Figure 1
The IPS architecture symbolizes, or rather materializes, the existence of abstract, fixed and autonomous principles, and of parameters whose values vary according to the language, as described in the GB theory.
This architecture currently contains specifications for French ">FIPS, for English ">IPS, for Italian ">I-IPS and for German. Parser IPS (Laenzlinger & Wehrli 1991, Wehrli 1992) uses grammars based on the Chomskyan model of Government and Binding (Principles and Parameters). In its implementation, each grammar components correspond to a particular process. Some components such as the X-bar process, the chain composition process (A, A-bar, clitics) or the coordination process, are meant to generate structures. Others have a filtering function on these structures, like the assignment of cases or thematic functions. The information flow goes one-way from lexical structures to representations of semantic and pragmatic structures, as shown in Figure 2.
Figure 2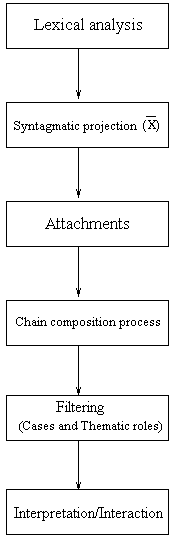
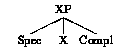
The semantic and pragmatic modules give an interpretation of all the structures as soon as possible, ie after each attachment. Should the interpretation modules be ineffective, the system can ask for the human user help and filter interactively the whole set of hypothesis on the basis of disambiguating dialogues. The basic module in this system is the X-bar module, which defines in a general and steady way the geometry of syntactic structures. The X-bar schema (somewhat simplified) is shown in (2), where X is a lexical or functional category, and Spec and Compl refer to (possibly empty) lists of maximal projections.
(2) The X-bar schema
The head shown as the X variable in (2) is either lexical (Adv, Adj, N, V, P), or functional (C, T, D, F).1 The sentence head being T(ense) (or Infl(ection)), a sentence phrase is represented as TP (Tense Phrase). The FP constituant (Functional Phrase) refers to functional structures, for example small clauses). Finally, the presence of a complementizer gives a CP projection (Complementizer Phrase). Thus, the canonical representation of a sentence is the one shown in (3).
(3)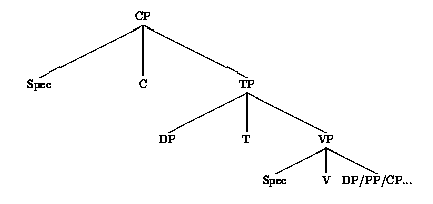
The C° position is the complementizer position, whether this complementizer is lexical or not. The Spec position of CP is the one assigned to interrogative phrases put in front of the sentence. The Spec position of TP is assigned to the subject, while the head T is assigned to a conjugated simple verb (or auxiliary). The participle is placed in position V. The Spec position of VP is typically assigned to adverbs. Finally, the Compl position of V is assigned to verb complementizers, eg a direct object (DP), an indirect object (PP) or a clause (CP).
The analysis algorithm includes a lexical analysis whose aim is to divide the entry sentence into lexical units. These units will be the base for a syntactic analysis assigning one or more syntactic structure(s) to the sentence.
The strategy of analysis is a left-to-right one with a parallel processing of alternatives, combining an incremental, essentially ascending approach with a descending filter. The analyzer will seek to associate the words of a sentence, one after the other, to constituents and sub-constituents of their left-side context.
Like all our software, IPS was written in Modula-2.
1 The terminology used for this system includes the following abbreviations which are assigned to the various constituants: Adj(ective), Adv(erb), N(oun), V(erb), P(reposition), D(eterminer), C(omplementizer), T(ense), F(unctionnal). [Back to main text]
The idea of using a computer to translate a text from a source language to a target language is nothing new. A lot of research was done in this field in recent years, but its results were always rather disappointing (few translation systems were trustable). From this observation, the idea of the ITS-2 project was to associate man and machine in the process of translation - in other words, to develop interactive translation. A computer program translates a text (a set of sentences) with the assistance of its user who will be ask to provide complementary information and clarifications. The translation tool is integrated in the MS-Windows environment and operates in the French, English and German languages.
The system is based on the IPS parser and operates as follows: the translation process begins by a lexical and syntactic analysis, which defines the nature of the lexical elements and sets the syntactic structure of the sentence, while specifying the gramatical roles of its constituents. From this analysis and the lexical information associated to the various phrase heads, it becomes possible to recognize the logical structure of the sentence in terms of relationship between the predicate (the verb) and the arguments (its subject and complements). On the basis of this logical structure, the transfer process into the target language begins, and a target logical structure is defined, from which a well-formed syntactic structure is derived by applying transformation rules. Finally, the system sets the right morphological (spelling) form of the various translated words.
webmaster