Les travaux de recherche entrepris au LATL ces dernières années ont principalement porté sur des problèmes liés au traitement de la syntaxe des langues naturelles, à la fois dans une perspective de recherche pure, et dans une perspective d'application à des problèmes typiques des industries de la langue. Ces travaux ont abouti d'une part à l'élaboration d'un modèle cognitif d'analyse (cf. Walther 1997), et d'autre part à la réalisation d'analyseurs syntaxiques (anglais, allemand, français...)(cf. Wehrli 2007), s'appuyant sur des modèles chomskyens de linguistique formelle. Ces outils d'analyse, et les bases lexicales qui les accompagnent, constituent les outils fondamentaux sur lesquels s'articulent plusieurs projets de développement de prototypes et de systèmes de traitement de la langue, aussi bien écrite que parlée.
Le projet Fips consiste à développer des analyseurs syntaxiques pour différentes langues, basés sur le modèle linguistique de la théorie GB.
Les objectifs du projet Fips sont à la fois théorique et pratique. D'une part, il s'agit de mettre en évidence la faisabilité et les interêts que présente, pour l'analyse syntaxique automatique, le choix d'une approche basée sur une théorie linguistique modulaire, qui substitue des principes généraux aux règles spécifiques des grammaires syntagmatiques traditionnelles. D'autre part, le projet vise à développer un analyseur syntaxique puissant, susceptible d'utilisations pratiques dans le domaine du traitement automatique du langage, et en particulier en traduction assistée par ordinateur ou en traitement de la parole.
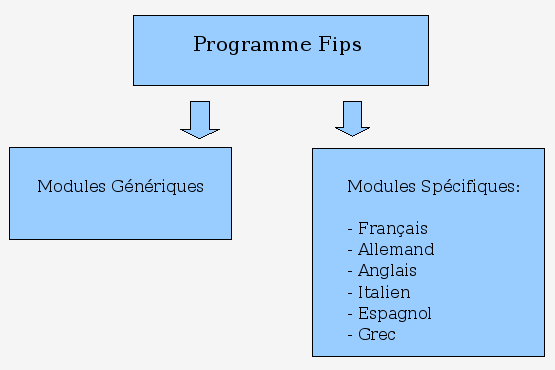
D'un point de vue pratique, le programme est unique et se compose de modules génériques (communs à toutes les langues) et de modules spécifiques à chaque langue, tels que représentés dans la figure (1) ci-dessous.
Figure 1
L'architecture de Fips symbolise, ou tout au moins concrètise l'existence de principes abstraits, fixes et autonomes, et de paramètres dont les valeurs varient selon les langues, tels que stipulés par la théorie GB.
Actuellement Fips contient des modules d'analyse pour le français , l'anglais, l'allemand, l'espagnol, et aussi le grec. L'analyseur Fips (Wehrli 2008, Laenzlinger & Wehrli 1991) utilise des grammaires inspirées du modèle chomskyen Gouvernement et Liage (Principes et Paramètres). Dans l'implémentation de cet analyseur, les composants de la grammaire correspondent à des processus particuliers. Certains sont générateurs de structures, comme le processus X-barre, le processus de formation des chaînes (A, A-barre, clitiques), le processus de traitement de la coordination; d'autres exercent une fonction de filtre sur ces structures, comme l'assignation des cas et des fonctions thématiques. Le flot d'information est unidirectionnel et va des structures lexicales aux représentations des structures sémantico-pragmatiques, comme l'illustre la figure (2).
Figure 2
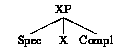
Les modules sémantiques et pragmatiques interprètent l'ensemble des structures le plus rapidement possible, c'est-à-dire après chaque attachement. A défaut des modules d'interprétation, le système peut requérir l'aide de l'usager et filtrer l'ensemble des hypothèses de façon interactive sur la base de dialogues de désambiguisation.Le module de base de ce système est le module X-barre, qui dicte de façon générale et uniforme la géométrie des structures syntaxiques. Le schéma X-barre (quelque peu simplifié) est donné en (2), où X est une catégorie lexicale ou fonctionnelle, et Spec et Compl correspondent à des listes (éventuellement vides) de projections maximales.
(2) Le schéma X-barre
La tête représentée comme la variable X en (2) est soit lexicale (Adv, Adj, N, V, P), soit fonctionnelle (C, T, D, F).1 La tête de la phrase étant T(ense) (ou Infl(ection)), un syntagme phrase est noté TP (Tense Phrase). Le constituant FP (Functional Phrase) correspond à des structures fonctionnelles, p.ex. les propositions réduites (small clause). Enfin, une phrase dotée d'un complémenteur est une projection CP (Complementizer Phrase). Ainsi, la structure canonique d'une phrase sera celle en (3).
(3)
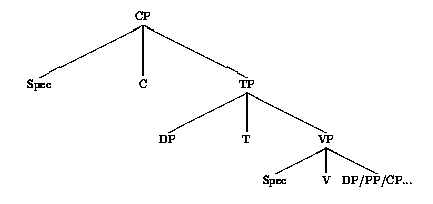
La position C° est celle du complémenteur, lexical ou non. La position Spec de CP est celle attribuée aux syntagmes interrogatifs antéposés. La position Spec de TP est celle du sujet, alors que la tête T° est occupée par un verbe simple (ou un auxiliaire) conjugué. Le participe occupe la position V°. La position Spec de VP est typiquement celle des adverbes. Finalement, la position Compl de V° accueille les compléments de verbe, par exemple un objet direct (DP), un objet indirect (PP), ou une proposition (CP).
L'algorithme d'analyse comprend une analyse lexicale, responsable de la segmentation d'une phrase d'entrée en unités lexicales, servant de base à une analyse syntaxique, qui assigne à une phrase une ou plusieurs structures syntaxiques.
La stratégie d'analyse est de type gauche-droite avec un traitement parallèle des alternatives, combinant une approche incrémentale, essentiellement ascendante avec un filtre descendant. L'analyseur tente d'associer les mots d'une phrase, les uns après les autres, à des constituants ou sous-constituants de leur contexte gauche.
Fips a été écrit en Component Pascal .
1 La terminologie utilisée pour ce système comprend les abréviations suivantes pour représenter les constituants: Adj(ective), Adv(erb),N(oun), V(erb), P(reposition), D(eterminer), C(omplementizer), T(ense), F(unctionnal). [Retour à l'appel de note]
L'idée de recourir à l'ordinateur pour traduire un texte d'une langue (la langue source) dans une autre langue (la langue cible) n'est pas nouvelle. De nombreux travaux ont été effectués dans ce domaine ces dernières années, dont les résultats se sont améliorés mais restent parfois médiocres (peu de traductions fiables). Sur la base de ce constat, s'est établie l'idée du projet ITS-2 (cf. Nerima et Wehrli 2008). L'outil de traduction fonctionne sous Windows, et porte sur le français, l'anglais et l'allemand, l'italien, l'espagnol et le japonais.
Le système est basé sur l'analyseur Fips et fonctionne de la sorte: la traduction commence par une analyse lexicale et syntaxique, qui détermine la nature des éléments lexicaux et dégage la structure syntaxique de la phrase, tout en spécifiant les rôles grammaticaux des divers constituants. Cette analyse et les informations lexicales associées aux têtes syntagmatiques permettent de déterminer la structure logique de la phrase, exprimée sous forme de relation entre prédicat (le verbe) et arguments (son sujet et ses compléments). Sur la base de cette structure logique on effectue le transfert vers la langue cible et on détermine une structure logique cible, de laquelle on dérive une structure syntaxique bien formée au moyen de règles de transformation. Enfin, on spécifie la forme morphologique (orthographique) correcte des divers mots traduits.