Die Aktivitõten, die in den letzten Jahren am LATL durchgef³hrt worden sind, befassten sich hauptsõchlich mit der Problematik, die im Zusammenhang mit der Syntaxanalyse der nat³rlichen Sprachen steht. Dies sowohl unter dem Gesichtspunkt der reinen Forschung, als auch mit dem Ziel, sich der typischen Probleme der Sprachverarbeitung zu widmen. Gest³tzt auf Chomskys Modell der formalen Linguistik haben diese Aktivitõten einerseits in der Entwicklung eines kognitiven Modells der Sprachanalyse (cf. Walther 1997) und andererseits in der Entwicklung von Syntaxparsern gem³ndet (f³rs Englische, Deutsche, Italienische und Franz÷sische). Diese Werkzeuge und die Lexika, die sie begleiten, bilden die grundlegenden Hilfsmittel auf denen sich verschiedene Projekte zur Entwicklung von Prototypen und von Verarbeitungssystemen, sowohl geschriebener als auch gesprochener Sprache, st³tzen. Zu diesen Projekten geh÷ren:
Der Parser FIPS wird im Rahmen der GRACE-Evaluation ebenfalls als Tagger benutzt. Im Rahmen von SAFRAN, einem ARP-Projekt des AUPELF, in Zusammenarbeit mit UMist/Manchester, ENST/Paris, IDIAP/Martigny und der Universitõt Sofia, ist der Parser in ein System f³r den computerunterst³tzten Sprachunterricht f³rs Franz÷sische integriert.
Das IPS-Projekt hat, basierend auf dem Modell der linguistischen Rektions- und Bindungstheorie (Government and Binding, GB), die Entwicklung von Syntaxparsern f³r verschiedene Sprachen zum Ziel. Die Zielsetzungen des IPS-Projektes sind sowohl theoretischer als auch praktischer Natur. Einerseits geht es darum, bei der automatischen Syntaxanalyse, die Machbarkeit und das Interesse zu Unterstreichen, welches in der Wahl eines Ansatzes besteht, welcher auf einer modularen Linguistiktheorie basiert, die die spezifischen Regeln einer Phrasenstrukturgrammatik durch allgemeine Prinzipien ersetzt. Andererseits zielt das Projekt auch auf die Entwicklung eines leistungsstarken Syntaxparsers hin, welcher in praktischen Anwendungen im Bereich der maschinellen Sprachverarbeitung, insbesondere in der computerunterst³tzten ▄bersetzung oder der Verarbeitung der gesprochenen Sprache, Verwendung finden k÷nnte.
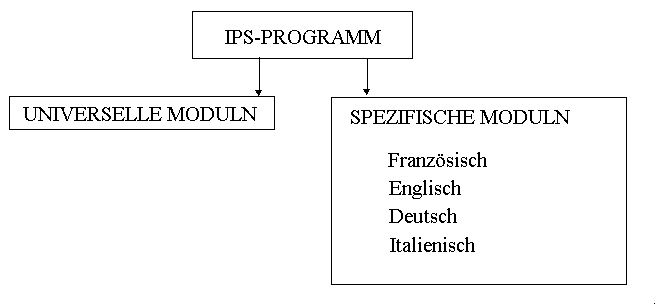
Aus praktischer Sicht bildet das Programm eine Einheit, die sich aus universellen (die allen Sprachen gemeinsam sind) und sprachspezifischen Modulen zusammensetzt. Die Struktur des Programms ist in der Abbildung (1) dargestellt.
Abbildung 1
Die Architektur von IPS symbolisiert das Vorhandensein abstrakter, fixer und autonomer Prinzipien und Parameter deren Werte je nach Sprache variieren, so wie sie in der Theorie von GB stipuliert sind.
Zur Zeit enthõlt sie die Spezifikationen f³rs Franz÷sische, (>FIPS), Englische (IPS), Italienische (I-IPS) und Deutsche.
Der Parser IPS (Laenzlinger & Wehrli 1991, Wehrli 1992) basiert auf einer Grammatik die am chomskyschen Modell der Rektions- und Bindungstheorie (Prinzipien und Parameter) inspiriert ist. In der Implementation dieses Parsers entsprechen die Bestandteile der Grammatik speziellen Prozessen. Einige generieren Strukturen, wie der X-quer-Prozess, der Prozess zur Bildung von Ketten (A, A-quer, Klitiken), und der Prozess zur Verarbeitung der Koordination; andere Prozesse erf³llen eine Funktion als Filter f³r diese Strukturen, zum Beispiel bei der Zuordnung der grammatischen Fõlle und der thematischen Rollen. Der Informationsfluss ist unidirektionell und erfolgt von den lexikalischen Strukturen zu den Reprõsentationen der semantisch-pragmatischen Strukturen, wie in der Abbildung (2) beschrieben.
Abbildung 2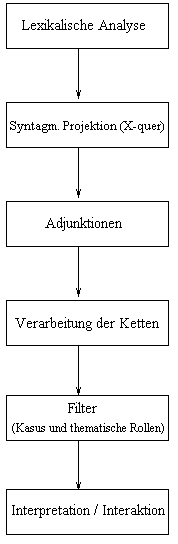
Das semantische und das pragmatische Modul interpretieren so schnell wie m÷glich alle Strukturen, das heisst nach jeder Adjunktion. Anstelle der Interpretationsmodule kann das System auch die Unterst³tzung des Benutzers anfragen, und somit in einem Desambiguierungsdialog die Hypothesen auf interaktive Art und Weise filtern. Das Grundmodul dieses Systems ist das X-quer-Modul, welches die Geometrie der syntaktischen Strukturen generell und gleichf÷rmig diktiert. Das X-quer-Schema ist in (2) (etwas vereinfacht) beschrieben. X ³bernimmt den Wert einer lexikalischen oder funktionalen Kategorie, Spec und Compl enstprechen (eventuell leeren) Listen von maximalen Projektionen.
(2) Das X-quer-Schema
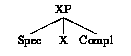
Der in (2) durch die Variable X dargestellte Kopf ist entweder lexikalischer (Adv, Adj, N, V, P), oder funktionaler (C, T, D, F) Natur. 1 Da der Kopf des Satzes T(ense) (oder Infl(ection)) ist, wird eine Satzphrase als TP (Tense Phrase) geschrieben. Die Konstituente FP (Functional Phrase) entspricht funktionalen Strukturen, z. B. den vereinachten Sõtzen (small clause). Zu guter letzt ist ein mit Komplement versehener Satz eine CP-Projektion (Complementizer Phrase). (3) beschreibt somit ist die Grundstruktur eines Satzes.
(3)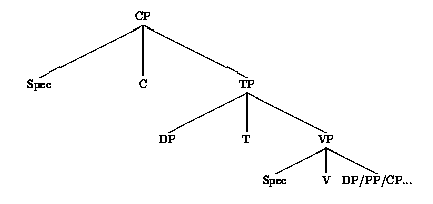
Die Position C░ ist diejenige des lexikalischen oder funktionalen Komplements. Die Spec-Position des CP ist diejenige der vorangestellten interrogativen Syntagmen. Die Spec-Position des TP ist diejenige des Subjekts, wõhrend der Kopf T░ von einem einfachen konjugierten Verb, (oder einem Hilfsverb) besetzt wird. Das Partizip befindet sich in der Position V░. Die Spec-Position des VP ist typischerweise diejenige des Adverbs. Zu guter letzt ist die Compl-Position des VP diejenige, welche die Komplemente des Verbs beherbergt, wie z. B. das direkte Objekt (DP), ein indirektes Objekt (PP) oder einen Nebensatz (CP).
Der Parsingalgorithmus umfasst eine lexikalische Analyse, welche f³r die Segmentierung des Eingabesatzes in lexikalische Einheiten verantwortlich ist. Die lexikalischen Einheiten bilden wiederum die Basis f³r die Syntaxanalyse, welche einem Satz eine oder mehrere Syntaxstrukturen zuordnet.
Die Parsingstrategie erfolgt von links nach rechts. Sie verfolgt alle Alternativen in einem parallelen Verfahren und verbindet ein inkrementelles, hauptsõchlich bottom-up orientiertes Verfahren mit einem top-down-Filter. Der Parser versucht die W÷rter eines Satzes, eines nach dem anderen, zu Konstituenten oder zu Unterkonstituenten ihres linken Kontextes zusammenzuf³hren.
Wie alle unsere Programme ist IPS in Modula-2 geschrieben .
1 Die in diesem System verwendete Terminologie umfasst die folgenden Abk³rzungen um Konstituenten zu bezeichnen: Adj(ective), Adv(erb), N(oun), V(erb), P(reposition), D(eterminer), C(omplementizer), T(ense) , F(unctionnal). [Zur³ck zum Fussnotenzeichen]
Die Idee auf einen Computer zur³ckzugreifen um einen Text in einer Sprache (Originalsprache) in eine andere Sprache (Zielsprache) zu ³bersetzen ist nicht neu. In diesem Bereich sind bereits viele Arbeiten durchgef³hrt worden, welche allerdings nur zu mittelmõssigen Resultaten gef³hrt haben (geringe Anzahl zuverlõssiger ▄bersetzungen). Aufgrund dieser Erkenntnis ist die Idee entstanden, im ITS-2-Projekt der Maschine einen Menschen hinzuzugesellen, um einen interaktiven ▄bersetzungsprozess zu erm÷glichen. Das Computerprogramm ³bersetzt einen Text (satzweise) mit der Unterst³tzung des Benutzers, welcher nach zusõtzlichen Informationen und Erlõuterungen gefragt wird. Das ▄bersetzungswerkzeug ist in der Oberflõche von MS-Windows integriert und lõuft f³rs Franz÷sische, Englische und Deutsche.
Das System basiert auf dem IPS-Parser und funktioniert folgendermassen: Der ▄bersetzungsprozess beginnt mit einer lexikalischen und einer syntaktischen Analyse, welche die Natur der lexikalischen Elemente und die Syntaxstruktur des Satzes festlegt, wobei die grammatikalischen Rollen der Konstituenten spezifiziert werden. Diese Analyse und die Informationen, welche den K÷pfen der Phrasenstrukturen zugeordnet sind, erm÷glichen es, die logische Struktur des Satzes auszudr³cken, welche in Form einer Relation zwischen Prõdikat (Verb) und Argumenten (Subjekt und Komplemente) zu ermitteln. Auf der Basis dieser logischen Struktur wird der Transfermechanismus in Richtung Zielsprache ausgef³hrt. Hierbei wird eine logische Struktur f³r die Zielsprache ermittelt, von der aufgrund von Transformationsregeln eine korrekte Syntaxstruktur abgeleitet wird. Zu guter letzt wird die korrekte morphologische (orthographische) Form der ³bersetzten W÷rter spezifiziert.